Data: A before and after story
In 2012, I published research quantifying operational risk from real-time sensor data using methods borrowed from earthquake engineering. What followed was a decade-long before and after: the same methodology, transformed by better data foundations. A practitioner's view on why digital transformation is a data problem as much as a technology problem.
Yezid Arevalo
5/8/20263 min read
From Sparse Data to Scaled Intelligence: A Before and After
In 2012, I published research on quantifying operational risk in real time from sensor measurements. The methodology was rigorous, the results were validated, and the approach worked. But the data available to support it was severely constrained.
What followed over the next decade, across a series of roles that progressively moved from analytics and product development into enterprise data programme delivery, gave me a direct, first-hand experience of the before and the after.
Doing it before it had a name
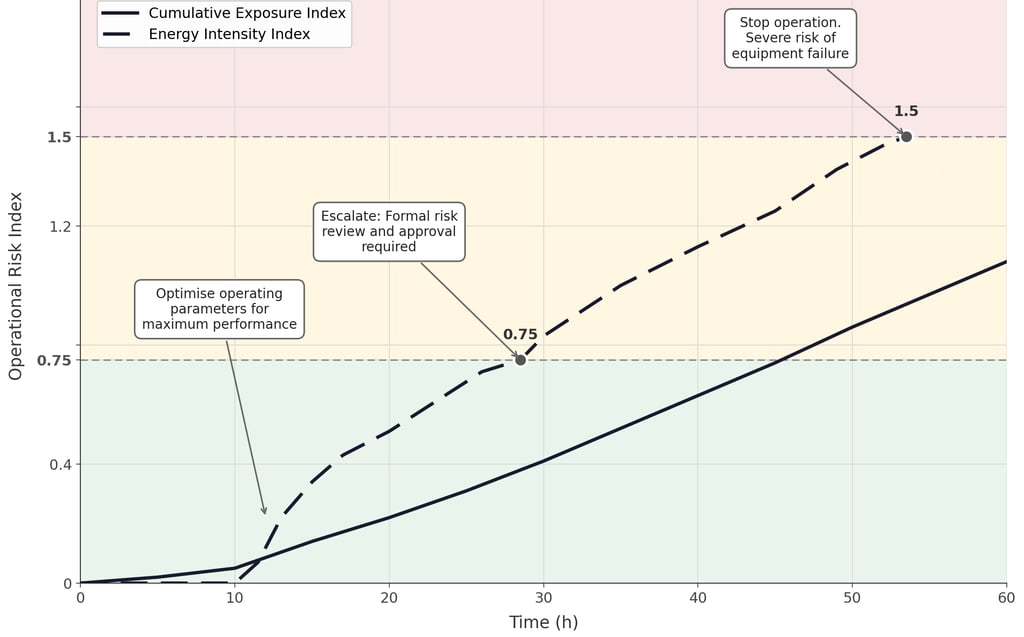
The work behind that 2012 paper was not called data science at the time. It was engineering analysis applied to an operational problem. The question was straightforward in principle and genuinely hard in practice: how do you convert continuous real-time sensor measurements into a single, interpretable risk signal that can guide a decision during an active operation?
The approach leveraged techniques from geotechnical earthquake engineering, a field that had spent decades solving an analogous problem: how to quantify the destructive potential of ground motion on a structure, not from a peak measurement, but from accumulated exposure over time. We adapted that mathematical framework to a completely different physical context. The domain changed. The underlying problem structure did not.
This point extends well beyond the specific work. Scientific methods are not sector-specific. The validity of an analytical approach is determined by the structure of the problem it addresses, not by the industry in which it was first developed. Wherever a complex system operates under continuous stress, generates real-time observable data, and carries meaningful consequences for failure, the same methodological logic applies. That includes industrial operations, infrastructure management, clinical environments, and regulated research settings.
What the data constraint actually meant
The 2012 results demonstrated that approximately 80% of failures in the analysed dataset could be identified in advance from sensor data alone, with a single measurement location and no prior knowledge of component condition. That was a meaningful result.
But the dataset was small. Data arrived at low frequency. Calibration of the risk thresholds depended on a limited number of documented cases. The outputs were valid, but interpreting and acting on them required experienced human judgement at each step. The methodology was ready. The data infrastructure beneath it was the constraint.
This distinction, between methodological readiness and data readiness, is a frequently underestimated gap in operational analytics. A technically sound approach applied to an immature data foundation will deliver limited results, require disproportionate expert effort to operationalise, and fail to scale. That was the reality in 2012.
The Before and After
The same sensing environment, and a methodology that continued to develop as the data supporting it grew, progressively had access to datasets that were two orders of magnitude larger. Capture frequency increased. Historical records grew from hundreds of cases to hundreds of thousands. What had required specialist interpretation at each data point became computable continuously and automatically.
The result was not just higher predictive accuracy. It was a genuinely different way of running the operation. Teams can now make confident data-driven decisions, without needing a specialist in the loop at every step. The value of the methodology and its evolution became fully realisable only when the data foundation beneath it was capable of supporting it at speed and at scale.
This is not an observation from the outside. I lived it directly. I developed the methodology under constrained data conditions. My subsequent roles took me through the whole of that shift, from analytics and product delivery through to leading the development of the enterprise data foundations that make scaled, high-frequency operational intelligence possible. The last of those roles was specifically focused on building the data infrastructure, covering capture, quality, accessibility, classification, and alignment, that makes analysis at speed possible in the first place.
This before and after runs through every role I have held since.
What this means for today's digital agenda
Organisations across every sector are investing in AI, machine learning, and real-time analytics. Many have sound methodological approaches. Many are also constrained by the same thing that constrained the 2012 work: data that is insufficiently captured, inconsistently structured, difficult to access, or ungoverned at the point of use.
The digital transformation is not primarily a technology problem. It is a data foundation problem. The analytical capability to extract value from operational data has been available, in various forms, for longer than most organisations realise. What determines whether that capability can be deployed at the speed and scale that today's environment demands is the quality, completeness, and accessibility of the data supporting it.
That is what I mean when I talk about data foundations as a critical enabler, not as infrastructure for its own sake, but as the thing that closes the gap between a methodology that works in principle and a system that delivers reliably in practice.
Original peer reviewed paper: Arevalo, Y. and Fernandes, A. (2012). Quantification of Drillstring-Integrity-Failure Risk Using Real-Time Vibration Measurements. SPE Drilling and Completion, 27(02), 216-222. DOI: 10.2118/147747-PA